
常用古籍全文数据库
荀子说:“君子生非异也,善假于物也。”
得益于互联网和数据库技术的发展,文史研究已经日益借力于数据库,并呈现出由数据库逐步向知识库转变的鲜明趋势。以下列举当下中国文史研究必备的古籍全文数据库,各具特色和优势,相得益彰。从使用者角度来看,衡量古籍库的主要因素为大容量、准确性、便利性、整合性、智能性。数据库开发者仍在不断拓展完善现有数据库。
数据库是按照数据结构来组织、存储和管理数据的仓库。大容量才能满足尽可能多的数据需求。下图以三大古籍库为例,截止2023年初,“中国基本古籍库”已升级到V8.0版,“中华经典古籍库”也以每年一次的扩展速度更新到第10期,“鼎秀古籍全文检索平台”已升级到2.0版,名为“文心阁古籍数据库”,在原“鼎秀古籍全文检索平台”21,000种古籍基础上又增加了10,305种,古籍总数为31,305种,仍以数据扩展速度和超大容量保持绝对领先优势。但据《中国古籍总目》(中国古籍总目编纂委员会编,中华书局2012年出版)所著录的现存20万种中国古籍的总量来看,古籍数据库还有很大的提升空间。


“中华经典古籍库”依托中华书局创办的“籍合网”平台,以中华书局等16家专业出版社古籍图书为核心数据,同时借助“籍合网”平台组成以“中华经典古籍库”为核心的数据集群。这些数据库中的绝大部分都是由“籍合网”提供平台和技术、由专家提供相关数据合作而完成的。
“中国基本古籍库”依托北京爱如生数字化技术研究中心,采用古籍数字化再造技术,对不同时代、不同尺寸、不同版式、不同字体的各类古籍刻本、抄本、写本、稿本和批校本进行数字化处理,制成既保持原貌,又可以进行检索和编辑的数字文本,使其以数据库的形式,再现于计算机和网络。已取得《中国方志库》初集二集、《中国谱牒库》初集二集、《中国金石库》初集、《中国丛书库》初集、《中国类书库》初集、《中国辞书库》、《儒学经典库》初集、《道教经典库》初集、《中国俗文库》初集、《历代别集库》四集、《敦煌文献库》初集等阶段性成果。 二、基本古籍数字定本工程 此工程于2009年启动,其目标是达成足堪信赖并可以直接引用的数字善本。工程分2个部分进行,第一个部分是对一千种核心古籍(如十三经 、二十四史、先秦诸子 、历代名家集)的数字文本精审细校,实现零错误率,确保其可以直接引用;第2个部分是对九千种基本古籍(各学科基本文献)的数字文本逐字勘改,实现万分之一以下的错误率,确保其符合或好于国家标准。
“鼎秀古籍全文检索平台”,是一款实现全文检索的古籍典藏数据库,收藏国内外各古籍文献收藏单位和个人文献收藏者的古籍文献资源。 1、收录范围涉及广:广泛收录中国大陆及港澳台地区公共机构、私人藏家、研究机构及博物馆所藏历代古籍资源,特色古籍采录海外所藏中国古籍,尤以日本、韩国数量最多。 2、收录时间跨度长:收录从先秦至民国撰写并经写抄、刻印、排印、影印的历朝历代汉文古籍。 3、收录版本涵盖全:版本包含稿抄本、刻本、石印本、铅印本、活字本等均有收录。在版本选择时,尤以同类版本中保存良好的为先,要求书籍品相好,避免虫蛀、漫漶情况。 4、收录分类设置专:著录规则分类标准沿用“经、史、子、集”传统分类的基础上增设丛书部。 5、收录内容数量大:收录海量古籍文献。是全文检索古籍库中数量最为庞大的。
相较而言,“中国基本古籍库”与“鼎秀古籍全文检索平台”偏于资料性,在规模效应上具有较大优势;而“中华经典古籍库”偏于研究性,在合作与创新上具有较大优势。
准确性是古籍库的另一要件。“中华经典古籍库”的准确性最高。“中华经典古籍库”所收录数据资源为中华书局、凤凰出版社、华东师范大学出版社、上海书店出版社、上海书画出版社、浙江古籍出版社、浙江人民美术出版社、西泠印社出版社、天津古籍出版社、齐鲁书社、三晋出版社、巴蜀书社、辽海出版社、三秦出版社、岳麓书社、大象出版社等多家专业出版社已出版的古籍整理本,其纸本图书在教学和科研中已被广泛征引,学术性已得到学界普遍认可。“中华经典古籍库”以这些古籍整理图书为原始文本,利用计算机技术进行了精准的数字化编辑工作,对每一个标准字符集外的古籍用字都一一处理,并修改了原书中的一些错误,因此其数据质量相较纸版图书更优,且该数据库提供原版图书图片与数据库文字予以全面对照,页码一一对应,研究者可以放心地复制、引用相关文献,极大地节省了研究者录入、复核文献时所耗费的精力和时间,而可将主要精力放在文本研究上。
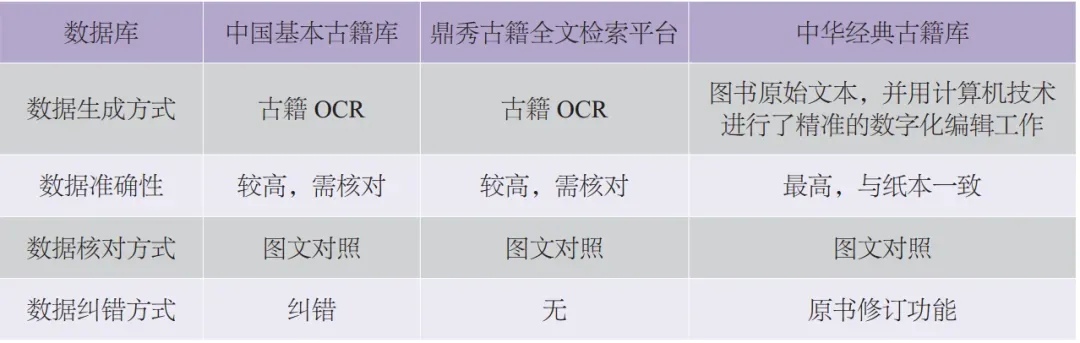
“中国基本古籍库”和“鼎秀古籍全文检索平台”二者性质较类似,所收数据均为先秦至民国的各类古籍文献的影印本图片及OCR数据。因为影印本的漫漶、模糊、缺损、页面误排等,尽管OCR数据经过了初步的人工核对,但其数据的准确性仍亟待提高,仍需要使用者与影印本图片仔细核对才能放心使用。同时,研究者除了仔细复核OCR数据外,还要进行自行断句、标点。因此,使用这种未经仔细校勘、整理的古籍OCR数据,既要求使用者要足够细心,又要求使用者有足够的小学句读能力。综合来看,与“中华经典古籍库”相比,“中国基本古籍库”和“鼎秀古籍全文检索平台”的数据在准确性和便利性上都存在较大的不足和差距。这也是“中华经典古籍库”后来居上,被众多研究者青睐的重要原因。
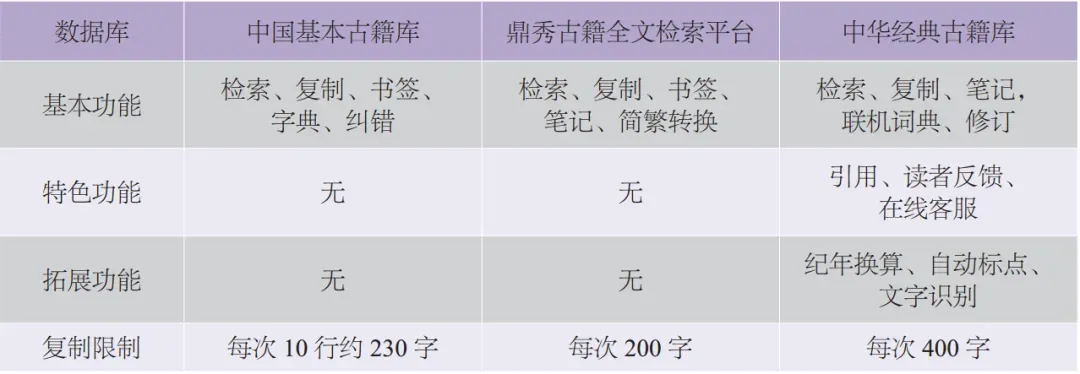
在特色功能方面,“中华经典古籍库”的引用功能极其便利,可以同时生成引用文献及引用格式(包括作者、书名、卷次、出版社、出版时间、页码等详细信息),这对于研究者来说极为便利实用。同时,“中华经典古籍库”还有读者反馈和在线客服,提供了便利的反馈渠道,便于使用者及时咨询,也便于数据库开发方及时发现问题。
在拓展功能方面,“中华经典古籍库”所在的“籍合网”平台还有纪年换算、自动标点、文字识别等工具。这些功能非常实用,进一步增加了数据库使用的便利性,也无疑提升了用户体验。以自动标点为例,“籍合网”的“自动标点”的准确率可达97%以上,研究者只需将主要精力放在个别错误标注处的修正上即可。“自动标点”已成为古籍整理者的得力助手,“自动标点的初加工+专家的仔细审核把关”将成为古籍整理的一种新通行方式。此外,“中华经典古籍库”中还有一种强大的拓展功能,即其古籍图书资源均已经研究者权威、深度整理,其标点、断句、分段、注、疏、眉批、专名、注释、系年、考证等研究成果可以直接促进中国古代文史教学与研究,可供师生借鉴、整理、汇总以往的古籍整理成果,展开进一步的科研工作。
全國古籍普查登記基本數據庫
全國古籍普查登記工作是“中華古籍保護計劃”的首要任務,中心任務是通過每部古籍的身份證——“古籍普查登記編號”和相關信息,建立古籍總台賬,全面瞭解全國古籍的存藏情況。“全國古籍普查登記基本數據庫”發佈的內容主要包括普查編號、索書號、題名、著者、版本、册數、館藏單位等信息。系統支持用戶按照題名、著者、版本、收藏單位、普查編號、索書號等字段進行簡單檢索(單一字段檢索)或高級檢索(組合字段檢索),支持繁簡共檢,檢索結果可按照普查編號和題名進行排序,同時可按照單位進行導航。國家古籍保護中心將根據普查工作進展,陸續發佈古籍普查數據。
书同文古籍数据库
北京书同文数字化技术有限公司成立于2000年,前身是《文渊阁四库全书》电子版工程中心,专注于中国经典古籍善本、历史文献档案的数字化以及汉字信息技术处理的应用研发、生产和销售。
尚古汇典
由上海古籍出版社研发运营的古籍数字化综合服务平台。以上海古籍出版社的古籍为主,同时收录上海世纪出版集团内、外相关出版机构的资源。包括上海辞书出版社、中西书局等出版机构。收录的资源涵盖经、史、子、集各部,包含“中国古典文学丛书”、“中国近代文学丛书”、“十三经注疏”、“清诗话”、“中国历代书目题跋丛书”、 “商周青铜器铭文暨图像集成”、历代大家全集、地方文献等经典系列,资源保留了图书的前言、注释、校勘等整理成果,数据准确,内容权威。已上线资源第一期共3亿字1170 种;第二期共2亿字507 种;第三期共3亿字1300余种。第四期共2亿字500余种,余2024年初上线。
瀚堂典藏數據庫
北京時代瀚堂科技有限公司是一家位於海淀上地北京留學人員海淀創業園區內的高科技公司,由在北美的留學人員回國創立。公司融合國內和北美地區先進的中英文資訊提取和中英文全文庫技術,包括自然中文處理、檢索引擎、知識管理、資料發現和檔案加密等先進技術,專注于中英文資料庫產品的引進和開發建設,及其在書刊出版、數據服務和檔案管理等行業的應用。依靠領先的技術、豐富的產品內容、優秀的本地化服務,獲得了廣大用戶的好評。
识典古籍
“识典古籍”是北京抖音信息服务有限公司开发和运营的古籍智能检索、阅读和整理平台。为促进中华古籍资源在网络环境下的利用与传播,抖音集团于2022年3月向北京大学教育基金会捐赠,支持古籍的数字化与智能化开发与利用。双方以“北京大学-字节跳动数字人文开放实验室”为合作平台,由北京大学数字人文研究中心提供设计指导和提供古籍图文数据。双方致力于向公众提供免费的古籍数字化平台,向社会开放访问。
汉典重光
“汉典重光”项目由阿里巴巴公益基金会、四川大学、美国加州大学伯克利分校、中国国家图书馆、浙江图书馆合作开展,旨在寻觅流散海外的中国古籍并将其数字化、公共化,通过古籍与先贤对话,与优秀传统文化对话。2019年,阿里巴巴和四川大学提出“数字化回归”设想,获得中文藏书量排名全美第三的加州大学伯克利分校支持并达成共识,将伯克利东亚图书馆的中文古籍善本逐步数字化。
汉籍数字图书馆
《汉籍数字图书馆》是陕西师范大学出版总社开发制作的大型汉字古籍数据库产品,由多位文、史、哲及技术专家历时十多年精心打造的正规网络出版物。于2010年正式出版发行,2016年9月最新成果“汉籍”2.0版全新上线,新版以服务读者古籍研究学习为核心理念,调整了核心数据库结构,优化了古籍目录与图版资源的组织架构,平台功能更加贴近读者需求,资源覆盖面大幅提升。

CBETA 漢文大藏經
中華電子佛典協會 (Chinese Buddhist Electronic Text Association 簡稱 CBETA) 由「北美印順導師基金會」、「菩提文教基金會」與「中華佛學研究所」於1998 年 2 月 15 日贊助成立。其目的為免費提供電子佛典資料庫以供各界作非營利性使用。2001年2月由「西蓮教育基金會」繼續協助此案的進行。CBETA 電子佛典集成以《大正藏》T01-55 & T85 為基礎,秉持「重複不錄」原則,針對《大正藏》以外現有各大藏經進行篩選,並汲取近代佛學研究整理成果,以建構一個完整的佛教漢文數位典藏。