
汉字字形的编码方法(原创)

统一字符编码标准Unicode是信息技术领域的业界标准,目的是为了整理和编码世界上大部分的文字系统(包含历史文献中的字符),使得电脑系统能以统一的字符集来处理和显示文字,减轻了过去在不同编码系统间切换和转换的困扰,并提供了一种跨平台的乱码问题解决方案。Unicode由非营利机构Unicode联盟(Unicode Consortium)负责维护。
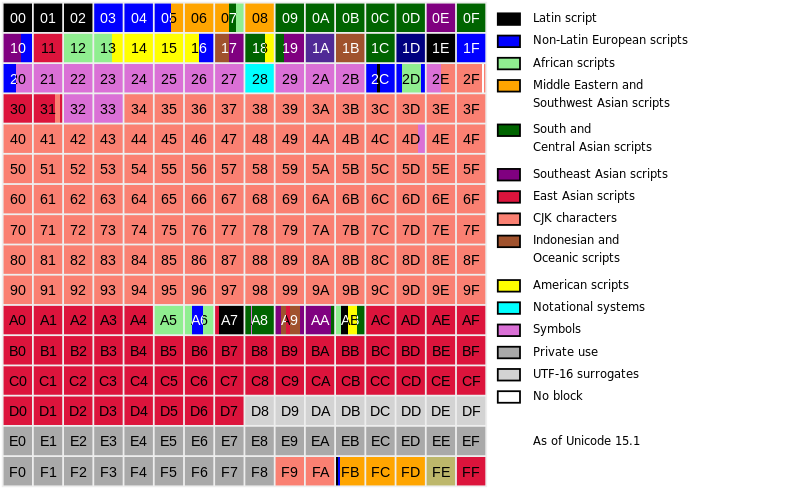
Unicode的编码方式是将编码空间分成 17 个平面(Plane),每个平面有65536(216)个码点(code point)。
| 平面 | 范围 | 中文名 | 英文名 |
|---|---|---|---|
| 0号 | 0000至FFFF | 基本多文种平面 | Basic Multilingual Plane,简称BMP |
| 1号 | 10000至1FFFF | 多文种补充平面 | Supplementary Multilingual Plane,简称SMP |
| 2号 | 20000至2FFFF | 表意文字补充平面 | Supplementary Ideographic Plane,简称SIP |
| 3号 | 30000至3FFFF | 表意文字第三平面 | Tertiary Ideographic Plane,简称TIP |
| 4号 至 13号 | 40000至DFFFF | (未启用) | |
| 14号 | E0000至EFFFF | 特别用途补充平面 | Supplementary Special-purpose Plane,简称SSP |
| 15号 | F0000至FFFFF | 保留作为私人使用区(A区) | Private Use Area-A,简称PUA-A |
| 16号 | 100000至10FFFF | 保留作为私人使用区(B区) | Private Use Area-B,简称PUA-B |
在第 0 平面,即基本多文种平面(Basic Multilingual Plane, BMP)中,CJK字符占有了近半数的码点。CJK字符是指基于汉字书写系统的中日韩同源文字。
Unicode的实现方式不同于编码方式,被称为Unicode转换格式(Unicode Transformation Format, UTF)。出于节省空间和提升传输效率的目的,可以选用不同的编码方式。
例如,对于一个仅包含基本7位ASCII字符的Unicode文件,如果每个字符都使用2字节的原Unicode编码传输,其第一字节的8位始终为0。这就会造成比较大的浪费。对于这种情况,可以使用UTF-8编码,这是一种变长编码,它将基本7位ASCII字符仍用7位编码表示,占用一个字节(首位补0)。当遇到与其他第0平面的Unicode字符混合的情况时,可以按一定算法转换,将每个字符使用1~3个字节编码,并利用首位为0或1来标识。类似的,对需要4个字节的辅助平面字符,2字节编码的UTF-16也需要通过一定的算法进行转换。
Unicode标准中的汉字字符编码
Unicode中跟汉字相关的编码涉及多个平面,统称为UniHan, 目的是为了将基于汉字书写系统的同源文字统一在一起。包含了汉字及其派生出来的意音文字,包括繁体字、简化字、日本汉字(漢字/かんじ)、韩国汉字(漢字/한자)、琉球汉字(漢字/ハンジ)、越南的喃字(𡨸喃/Chữ Nôm)与儒字(𡨸儒/Chữ Nho)、方块壮字(𭨡倱/sawgun)等。官方文档在 http://www.unicode.org/reports/tr38/。
在UniHan标准中,除了第0平面的CJK字符以外,还包括第二辅助平面,也称表意文字补充平面(Supplementary Ideographic Plane, SIP),范围在U+20000至U+2FFFF,配置的都是罕用汉字或地区方言用字。还包括第三辅助平面,也称表意文字第三平面(Tertiary Ideographic Plane, TIP),规划用于摆放甲骨文、金文、小篆、战国文字等,范围在U+30000至U+3FFFF。
在UniHan数据库中不仅定义了每个字的码点和字形,还包含其他信息,如拼音,异体字,笔顺,英文定义,部首,康熙字典部首等。
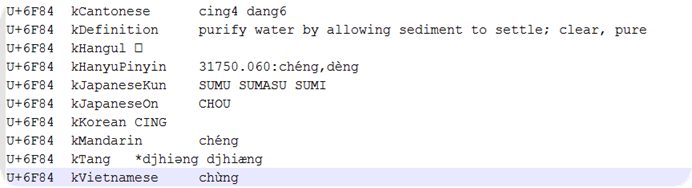
从上图中可以看到:广东话发音kCantonese,英语定义 kDefinition,現代漢語頻率詞典kHanyuPinlu,kHanyuPinyin是<漢語大字典>中对此字的发音定义,kMandarin是这个字在普通话中的常用发音(对多音字有意义), 现代汉语词典kXHC1983,以及其他语种的发音。
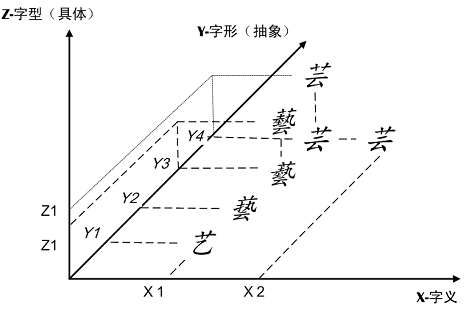
UniHan标准中有X,Y,Z三轴,意思就是所有汉字都可以定位在X,Y,Z三个坐标轴上,这是为了建立各个字形与其含义之间的关系。X轴代表字义,Y轴代表字形(Generic Glyph或Abstract Glyph),而Z轴就是字形的具体造型。如上图中,中文简体字“艺”与日文简体字“芸”,都是“藝”的简体。与异体字“
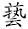
”都具有相同的含义(在X轴的投影为X1),但它们不能认同为一个编码汉字,而是在Y轴上的四个投影(Y1,Y2,Y3 和Y4);同样的,虽然“芸”至少还有一个含义(芸香,芸芸众生,X轴投影为X2),但它不能再有另一个代码。
汉字字形是形式(或“能指”),不是内容(或“所指”);相对于字型它是抽象形态,不是具体的造型。在上图中,“芸”和“
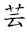
”,“藝”和“
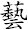
”虽然在草字头上有差异 、从而在Z轴上有不同的投影(Z1,Z2),但被视为Z轴上的微小差异,不影响其在Y轴的投影,因此代码不变。
汉字字形编码中存在的问题
- 收字过少
不同字形之字合并后,若以字形为本检索,会产生混乱,难以检索,如笔画检字,艸部之“艹头”,中国、日本算作三画,而传统中文为四画,留有“艸”形者则为六画。UniHan中同一字码源于字形不同就有几种笔画,检索混乱。即使检出字,笔画与显示出来的字形也不相符。因此,批评者认为,统一码合并异体字并不可取。
- 收字过多
汉字描述语言
The Chinese character description languages (CCDL) are several proposed languages to most accurately and completely describe Chinese (or CJK) characters and information such as their list of components, list of strokes (basic and complex), their order, and the location of each of them on a background empty square. They are designed to overcome the inherent lack of information within a bitmap description. This enriched information can be used to identify variants of characters that are unified into one code point by Unicode and ISO/IEC 10646, as well as to provide an alternative form of representation for rare characters that do not yet have a standardized encoding in Unicode or ISO/IEC 10646. Many aim to work for Kaishu style and Song style, as well as to provide the character's internal structure which can be used for easier look-up of a character by indexing the character's internal make-up and cross-referencing among similar characters.
Character Description Language (CDL) is an XML-based declarative language co-created by Tom Bishop and Richard Cook for the Wenlin Institute. It defines characters by the arrangement of components, which are not required to reflect the semantic or etymological history of the character. In order for a component to fit into the allotted portion of the whole character's square, A set of fewer than 50 strokes allow one to construct approximately 1,000 components, which may in turn describe tens of thousands of characters.
不同于西方文字系统,可以通过字母的线性组合形成单词,再连缀成句;我们的汉字系统是通过构字部件的平面组合形成汉字,再连缀成句的。很遗憾的是计算机是西方人发明的,规则定制也多以西方的习惯为原型,汉字的信息化只好削足适履,被动适应西方标准。
目前大部分的汉字字符集(包括 Unicode),对于汉字编码的处理大致为先搜集汉字,给予每个汉字唯一的数字编码。然而,汉字数量庞大,往往字集不完全。再加上汉字本身具有组合以及开放的特性,汉字使用者很有可能自造新字,因此不可能有一个字集可以搜集到所有汉字。可以用表意文字描述字符 (Ideographic Description Characters, IDC) 来描述某“字”如何以较简单的部件进行组合。
动态组字方法
基于这种考虑,Unicode 组织在 3.0 版本开始,对 CJKV 统一表意文字做了一个新的支持——表意文字描述序列 (Ideographic Description Sequences, IDS)。其目的是利用多种组合字符,来描述所定义的汉字内部构字部件的相对位置,从而精确表示生僻字(或未被电脑字符集收入的缺字)。

Ideographic Description Sequences (IDS) are sequences of characters that represent a Chinese character structure as defined by the Unicode standard.
| 编码 | 字符 | 意义 | 例字 | 序列 | 例字 | 序列 |
|---|---|---|---|---|---|---|
| U+2FF0 | ⿰ | 两部件由左至右组成 | 相 | ⿰木目 | 𠁢 | ⿰丨㇍ |
| U+2FF1 | ⿱ | 两部件由上至下组成 | 杏 | ⿱木口 | 𠚤 | ⿱𠂊丶 |
| U+2FF2 | ⿲ | 三部件由左至右组成 | 衍 | ⿲彳氵亍 | 𠂗 | ⿲丿夕乚 |
| U+2FF3 | ⿳ | 三部件由上至下组成 | 京 | ⿳亠口小 | 𠋑 | ⿳亼目口 |
| U+2FF4 | ⿴ | 两部件由外而内组成 | 回 | ⿴囗口 | 𠀬 | ⿴㐁人 |
| U+2FF5 | ⿵ | 三面包围,下方开口 | 凰 | ⿵几皇 | 𧓉 | ⿵齊虫 |
| U+2FF6 | ⿶ | 三面包围,上方开口 | 凶 | ⿶凵㐅 | 义 | ⿶乂丶 |
| U+2FF7 | ⿷ | 三面包围,右方开口 | 匠 | ⿷匚斤 | 𧆬 | ⿷虎九 |
| U+2FF8 | ⿸ | 两面包围,两部件由左上至右下组成 | 病 | ⿸疒丙 | 𤆯 | ⿸耂火 |
| U+2FF9 | ⿹ | 两面包围,两部件由右上至左下组成 | 戒 | ⿹戈廾 | 𢧌 | ⿹或壬 |
| U+2FFA | ⿺ | 两面包围,两部件由左下至右上组成 | 超 | ⿺走召 | 𥘶 | ⿺礼分 |
| U+2FFB | ⿻ | 两部件重叠 | 巫 | ⿻工从 | 𣏃 | ⿻木⿻コ一 |
| U+2FFC | ⿼ | 三面包围,左方开口 | 㕚 | ⿼叉丶 | 𬺹 | ⿼コ二 |
| U+2FFD | ⿽ | 两面包围,两部件由右下至左上组成 | 氷 | ⿽水丶 | 斗 | ⿽⺀十 |
| U+2FFE | ⿾ | 水平翻转 | 卐 | ⿾卍 | 𣥄 | ⿾正 |
| U+2FFF | ⿿ | 旋转 | 𠕄 | ⿿凹 | 𠄔 | ⿿予 |
另有两个描述符号并不在此区块内:
| 编码 | 字符 | 区块 | 意义 | 例字 | 序列 | 例字 | 序列 |
|---|---|---|---|---|---|---|---|
| U+303E | 〾 | 中日韩符号和标点 | 形似但不相等 | 㬵 (U+3B35) | 〾胶 (U+80F6) | 𫜵 | 〾爫 |
| U+31EF | ㇯ | 中日韩笔画 | 减去笔画 | 乒 | ㇯兵丶 | 𧰨 | ㇯豕一 |


如果所要表示的汉字的构字部件不止两个怎么办呢?类似用 “- + 1 2 3”表示“1+2-3”,这种“前缀表达式”可以将十六种 IDC 组合成 IDS 。如“ ⿸厂⿱今止 ”相当于“ ⿸厂(⿱今止) ”,即先对「今」和「止」做上下结构的拼合,再对这个拼合部件与「厂」做左上方的半包围拼合。更多组合示例:

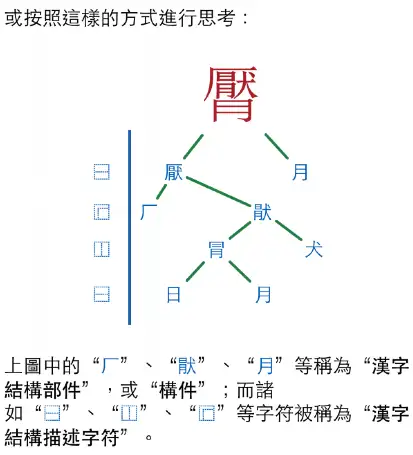
𰻝𰻝面
再比如:𰻝 biáng(⿺辶⿳穴⿲月⿱⿲幺言幺⿲長馬長戈心)
基于CDL的工具
Make Me a Hanzi
Free, open-source Chinese character data
 skishore
skishore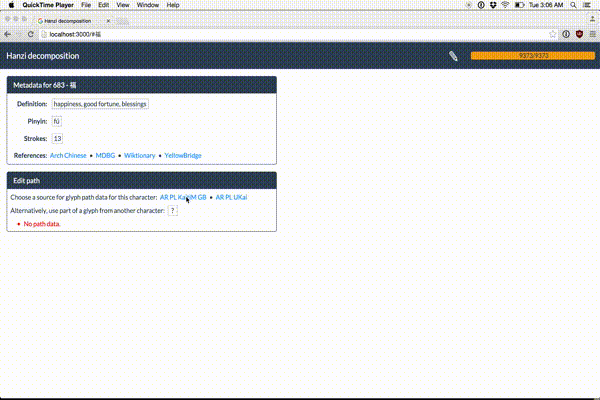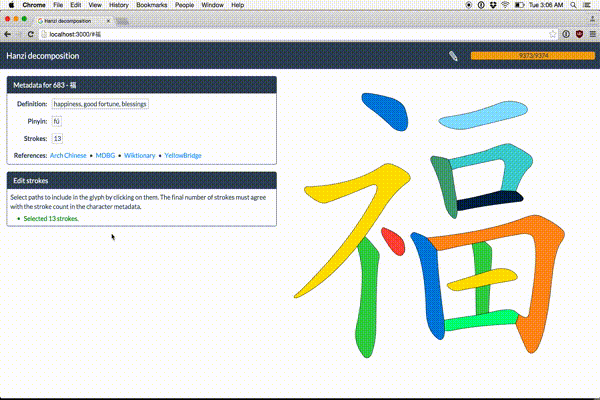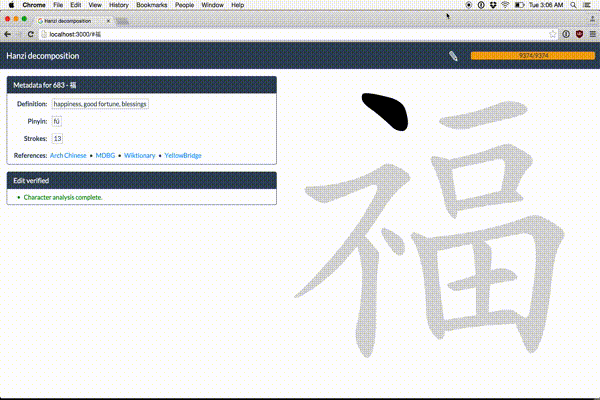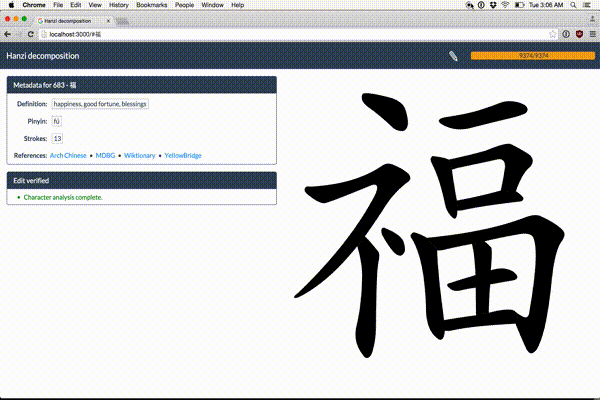
dictionary.txt keys:
- character: The Unicode character for this glyph. Required.
- definition: A String definition targeted towards second-language learners. Optional.
- pinyin A comma-separated list of String pronunciations of this character. Required, but may be empty.
- decomposition: An Ideograph Description Sequence decomposition of the character. Required, but invalid if it starts with a full-width question mark '?'.Note that even if the first character is a proper IDS symbol, any component within the decomposition may be a wide question mark as well. For example, if we have a decomposition of a character into a top and bottom component but can only recognize the top component, we might have a decomposition like so: '⿱逢?'
- etymology: An etymology for the character. This field may be null. If present, it will always have a "type" field, which will be one of "ideographic", "pictographic", or "pictophonetic". If the type is one of the first two options, then the etymology will always include a string "hint" field explaining its formation.If the type is "pictophonetic", then the etymology will contain three other fields: "hint", "phonetic", and "semantic", each of which is a string and each of which may be null. The etymology should be read as: ${semantic} (${hint}) provides the meaning while ${phonetic} provides the pronunciation. with allowances for possible null values.
- radical: Unicode primary radical for this character. Required.
- matches: A list of mappings from strokes of this character to strokes of its components, as indexed in its decomposition tree. Any given entry in this list may be null. If an entry is not null, it will be a list of indices corresponding to a path down the decomposition tree.This schema is a little tricky to explain without an example. Suppose that the character '俢' has the decomposition: '⿰亻⿱夂彡'The third stroke in that character belongs to the radical '夂'. Its match would be [1, 0]. That is, if you think of the decomposition as a tree, it has '⿰' at its root with two children '亻' and '⿱', and '⿱' further has two children '夂' and '彡'. The path down the tree to '夂' is to take the second child of '⿰' and the first of '⿱', hence, [1, 0].This field can be used to generate visualizations marking each component within a given character, or potentially for more exotic purposes.
graphics.txt keys:
- character: The Unicode character for this glyph. Required.
- strokes: List of SVG path data for each stroke of this character, ordered by proper stroke order. Each stroke is laid out on a 1024x1024 size coordinate system where:
- The upper-left corner is at position (0, 900).
- The lower-right corner is at position (1024, -124).
Note that the y-axes DECREASES as you move downwards, which is strage! To display these paths properly, you should hide render them as follows:
<svg viewBox="0 0 1024 1024">
<g transform="scale(1, -1) translate(0, -900)">
<path d="STROKE[0] DATA GOES HERE"></path>
<path d="STROKE[1] DATA GOES HERE"></path>
...
</g>
</svg>
- medians: A list of stroke medians, in the same coordinate system as the SVG paths above. These medians can be used to produce a rough stroke-order animation, although it is a bit tricky. Each median is a list of pairs of integers. This list will be as long as the strokes list.
HanziCraft
The Ultimate Chinese Character Dictionary
Inkstone
Learn Chinese on the go
skishore