
AI与碑刻数字化

在中华文明几千年的历史长河中,传承有浩如烟海的的珍贵古籍。这些古籍承载着丰富的历史、文化、政治、经济等方面的信息,蕴含着无可估量的价值。在古籍数字化的进程中,我国已完成了多项大型代表性项目,如“《四库全书》(文渊阁电子版)”、“汉籍电子文献全文资料库(台湾)”、“汉籍数字图书馆(陕师大)”、“中华经典古籍库(籍合网)”、“中国基本古籍库(爱如生)”和“文心阁古籍全文数据库(鼎秀古籍)”等。然而,至今仍有大量古籍尚未完成文字识别转录等工作,尤其是版面复杂的古籍,如家谱、地方志等。光学字符识别技术(OCR)可以识别古籍内容、文字,分析版面并进行结构化输出,这对于古籍的保护、检索,乃至信息挖掘和知识发现都具有深远意义。

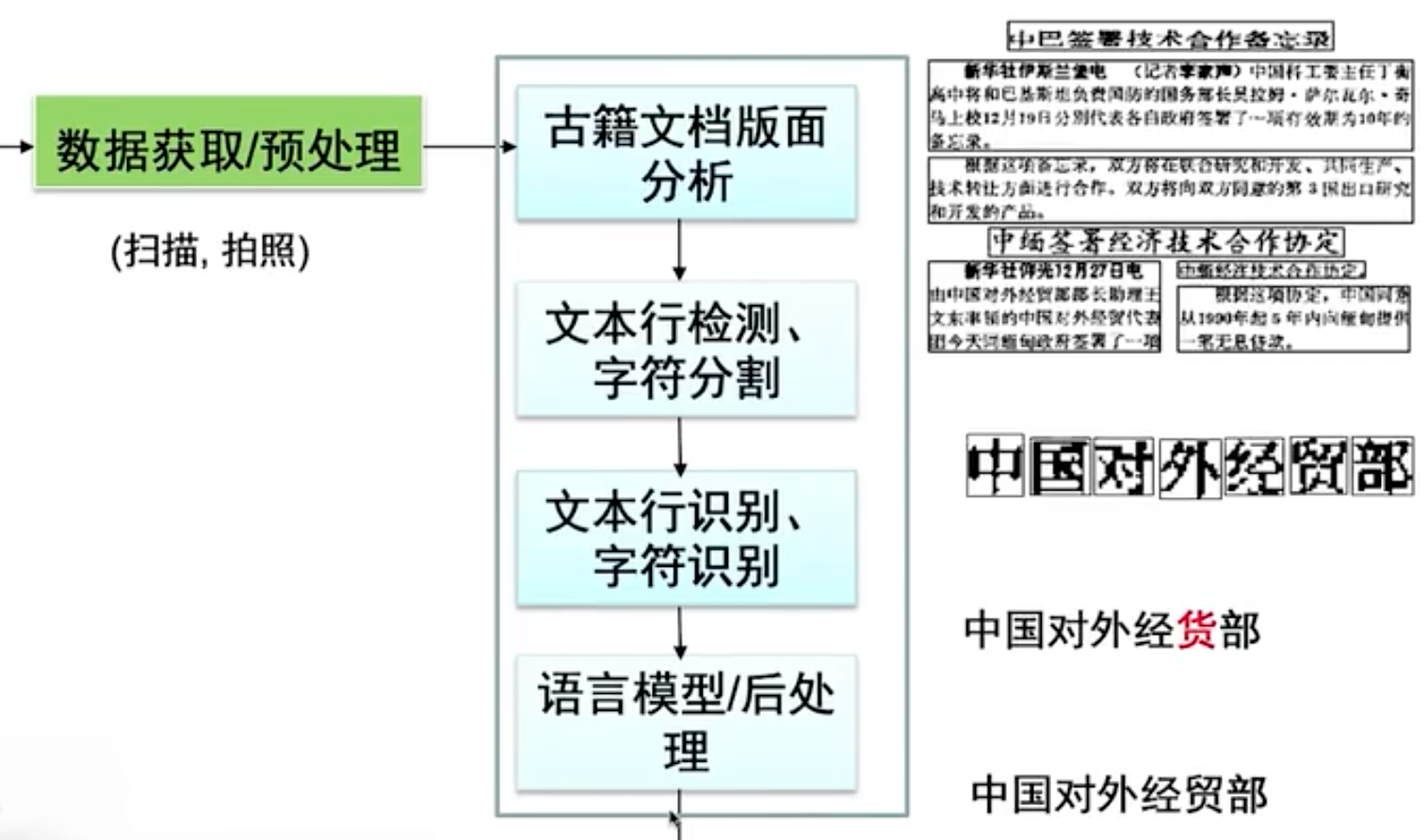
与常规OCR技术相比,古籍OCR的困难和挑战主要表现在古籍的图像质量退化、版式复杂、风格多样等方面。目前主流的OCR技术对于印刷体文字的识别率已经很高了,但不能直接应用于古籍OCR,主要原因在于目前缺乏高质量、大规模标注的数据,特别是中文的大规模公开数据集很少,版式数据集大部分也是西方古籍的。国内做得相对比较好的平台,如书同文公司的“i-慧眼OCR”,古联公司的“古联OCR”,北京如是的“如是古籍OCR”以及华南理工大学金连文老师团队与龙泉寺藏经办公室合作,基于汉文大藏经研发的中文古籍OCR识别引擎等。
碑刻数字化面临的问题
碑刻数字化是古籍数字化的一个细分领域,仍存在碑刻拓片难以大量收集的问题。碑刻数字化平台在国际上有:哈佛大学中国拓片数据库,淑德大学中国石刻拓本。国内较为知名的有:
- 中国国家图书馆的“碑帖菁华”中文拓片资源库,以馆藏的历代甲骨、青铜器、石刻等类拓片23万余件为基础建设,现有元数据2.5万余条,影像3.1万余幅。以刻立石年月排序,提供拓片的“题名”“责任者”“年代”“出土地点”“主题词”和“索书号”检索以及上述条件限定组合的高级检索;使用者可查询浏览所需拓片的扫描件与元数据(拓片上述属性的描述)。
- 北京书同文数字化技术有限公司的《中国历代石刻史料汇编》全文检索版,辑录了一万五千余篇石刻文献,并附有历代金石学家撰写的考释文字,总计约1,150万字。可以进行碑刻的三级纲目浏览(书—年代—碑名)与释文的全文检索。
- 古联(北京)数字传媒科技有限公司的《中华石刻数据库》。包含:
(1)《历代石刻拓片汇编》:通代性的石刻文献数据库。涵盖时期上起先秦,下至民国,全面收录、整合历代刻有文字的石刻资源;石刻类型丰富多样,内容题材包罗万象,涵盖碑碣、摩崖、墓志、墓砖、经幢、买地券、造像、画像砖等。本库文图兼收,支持录文与拓片参照阅读;对原文进行标点、分段;提供在线阅读、全文检索、复制引用、笔记批注等服务。
(2)《三晋石刻大全数据库》:由刘泽民、李玉明等主编。全书以抢救和存史为收录原则,以《三晋石刻总目》为基础,凡现存和佚失石刻均全文收录。全书以县(市、区)分卷,原则上每县(市、区)一卷,另有山西博物院卷、五台山卷、晋商会馆卷和总目各一卷,全省预计125卷。全卷录文分现存石刻和佚失石刻,分别按时代顺序排列,不分类。每件石刻编纂内容包括名称(全称)、简介、录文(全文),另附照片或拓片。收录的石刻文字,只作标点,不作校勘。全书兼具史料和艺术欣赏价值,可供相关研究者参考。
(3)《汉魏六朝碑刻数据库》:毛远明教授遗著《汉魏六朝碑刻集释》于2018年12月由中华书局进行数字出版,是现今汉魏六朝碑刻语言文字研究方面材料最翔实、成就最高的代表性著作。该数据库全面收集各类碑碣,制作成拓片图录;据图录准确释文,并加上现代标点;广集众本,精心校勘;对碑铭中的疑难词语简要注释和考辨,并辅以提要。作为碑刻文献整理研究成果,有材料收集全面、体例科学严谨、校勘准确精审的特点。
(4)《唐代墓志铭数据库》:《唐代墓志铭数据库》是专题性的石刻文献数据库。本数据库文、图兼收,对原文进行标点、分段,并实现全文检索。全面收集、整合隋唐五代各类墓志文献,利用已经搜集到的石刻拓片和已公开传世古籍以及已经出版整理的古籍(如各类全集、金石志等)等,不断完善数据库内容。
(5)《宋代墓志铭数据库》:《宋代墓志铭数据库》是专题性的石刻文献数据库。本数据库文图兼收,对原文进行标点、分段、考证,并实现全文检索。全面收集、整合宋代各类墓志文献,利用已经搜集到的石刻拓片照片和已公开传世古籍以及已经出版整理的古籍(如各类全集、金石志等)等,不断完善数据库内容。
- 北京师范大学的“中华碑刻典藏与汉字研究平台”,包含对近代碑刻资源(宋元明清)的搜集、整理、加工、保存、检索等功能。目前平台包括碑刻拓片6,600张,字形图22.5万张。该平台的主要特色是碑刻字形的采集与整理研究。主要包括以下四个功能:
(1)碑刻拓片的数字化典藏与管理:提供接口与规范,让各系列项目组可以将自己需要收藏的碑刻拓片扫描件置于平台的统一管理之下,实现真正的资源共享。
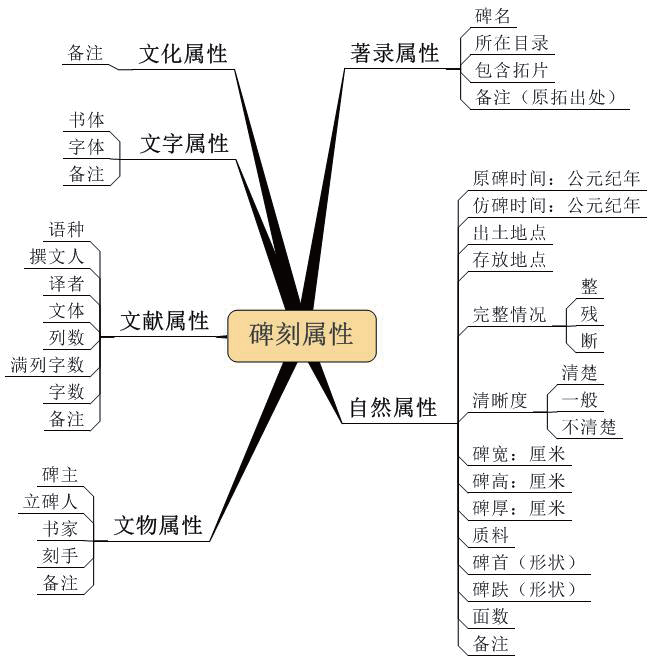
(2)碑刻属性的详细描述与基于属性的碑刻检索:提供对碑刻多元属性(如自然属性、文物属性、文献属性、文字属性、文化属性)的界定,从而可以根据不同的研究目标进行快速准确的碑刻检索。
(3)碑刻释文的录入与基于释文的全文检索:提供接口与规范,让各系列项目组可以进行碑刻拓片对应释文的录入,并据此实现碑刻内容的全文检索。
(4)碑刻实用字形的搜集整理与检索统计:基于碑刻字形研究需求所特别开发的功能,可以进行碑刻字形的切分,字样、字位和字种的归纳,从而实现对碑刻实用字形的检索与统计。
以“中华碑刻典藏与汉字研究平台”为例,分析碑刻数字化的元数据组织结构。其中,扫描的碑刻拓片、录入的释文与切分出的字形图片以三级目录的形式存放:第一层为碑刻的朝代,第二层为选取碑刻拓片的著录书,第三层为碑刻拓片在著录书中的分册。在三级目录下,以碑刻拓片为单位,存放其扫描件、释文文本与切分出的字形图片文件夹,一律采用拓片所在著录书中的页码作为文件(夹)名(如果一页中有多个拓片,则在页码后加“_序号”)。

拓片一律采用灰度扫描,分辨率设为300DPI,角度正中,边缘整齐,存储为JPG格式;释文一律存储为UTF-8编码的TXT文本格式,一列释文为一行,不计空格,单个模糊的字采用符号#代替,大段连续模糊的字则忽略;切分出的字形图片以其所在拓片中的“列_行”来命名,统一存放在与扫描件同名的子文件夹下。同时通过多元的属性结构从不同层面对碑刻进行描述,如下图所示。
除此之外,碑刻数字化在文本OCR方面还存在两大难题:
1.大量结构复杂多变的异构字,异构字识别的难点是标注样本少,种类多;
2. 不同朝代的刻写风格差异性大、风格多样;
3.严重的拓片图像质量退化问题,如残破、模糊、缺失、背景干扰等。
一、异构字识别
碑刻文本OCR的关键难点之一是字形的“认同别异”,这也体现出汉字(表意文字)与表音文字的区别。每个汉字字形由一个或多个构件(部件)组成,不同于拉丁语系的词根词缀,汉字构件之间的构成关系更为复杂且存在一定的不确性。如峰(U+5CF0)和峯(U+5CEF)的音和义均相同,构件“山”与“夆”也相同,仅仅因为构件的位置关系不同带来了字形的差异,构件的组合分别是⿰(代表左右结构)与⿱(代表上下结构)。在中文古籍中存在着大量这样的异构字,在OCR的过程中如何“认同别异”仍是一项复杂而艰巨的任务。
字形是指文字在文本中自然存在状态。严格说来,手写文本中不存在两个完全一样的字形。如何开展字形的“认同别异”工作,需要从“汉语文字学”入手。下面引用王宁老师在《汉字构形学导论》一书中对“汉字的认同”的定义。把没有区别意义的字形归纳在一起,叫做汉字的认同。她将共时汉字的认同分为三个层次:
(1)字样的认同:在同一种形制下,记录同一个词,构形、构意相同,写法也相同的字,称作一个字样。字样不计风格、不计大小、不计运笔和结体的特点,都可以加以认同,归纳到一起。
(2)字位的认同:在同一体制下,记录同一个词,构形、构意相同,仅仅是写法不同的字样,称作异写字,异写字认同后,归纳到一起,称为一个字位。
(3)字种的认同:形体结构不同而音义都相同、记录同一个词、在任何环境下都可以互相置换的字,称作异构字。异构字聚合在一起,称为一个字种。
以“明”这个字种为例,可以归纳为3个字位:“明、眀、朙”。其中,“明”可以作为代表字,“眀”和“朙”为“明”的异构字。可见,字位数是根据结构属性对字样进行的归纳,结构属性以直接构件为分析对象,直接构件的功能相同、组合关系和布局位置也相同的算作一个字位,同一字位中不具有结构功能区别价值的间接构件和具体写法可以不同。
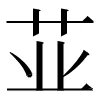
因此,我们认为碑刻字符OCR的对象是字位,每个字位一般有其对应的独立的Unicode编码,如明(U+660E)、眀(U+7700)、朙(U+6719)、𣇱(U+231F1)、𣷠(U+23DE0),更多的异体字可以参考《异体字字典》或《汉典》。更复杂的如并(U+5E76)存在更多的异构字:幷(U+5E77)、並(U+4E26)、竝(U+7ADD,校官碑)、傡(U+50A1)、併(U+4E75)、倂(U+5002)、𠀤(U+20024)、𢆙(U+22199)、𰏤(U+303E4)、𬿉(U+2CFC9),以及还未编入Unicode标准的字形:






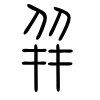
等等。
同时,一个字位使用次数的多少(字频),可以反映其在不同时代的文字系统中的地位和使用者的用字习惯。(通常把全部用字中见次率排在前10%的字叫高频字,见次率排在后10%的字叫低频字,其余为中频字。为什么这些字频次高,那些字频次低,需要从多方面考释原因。)
二、残缺字识别
碑刻文本OCR的关键难点之二是因为受到传拓方法、自然磨损、风雨侵蚀、地震断裂等因素的影响,拓本中往往存在严重的图像质量退化问题,如字形残破、背景噪声、文本缺失等。可以分别从以下两个方面进行处理:
(1)基于掩模合成/字形结构的自动修复


如上图所示,碑刻(拓片)图像质量退化带来的残缺字识别难题,主要表现在侵蚀带来的字形破坏(笔画和构件的缺失)和干扰(多余笔画)。传统的图像修复任务,往往已知待修复的掩模位置,可根据掩模周边的局部信息和图像的全局信息,完成掩模位置的自动修复。而碑刻残缺字的修复模型类似古籍修复专家,需要掌握字形结构和风格的先验知识,才能有效区分字形受到的破坏和干扰,继而完成字形自动修复任务。
需要特别注意的是,碑刻拓片不同于其他古籍,一方石碑可能存在不同时期的拓片,不同拓片之间因传拓技法和传拓时间的差异,携带了额外的附加信息。如上图(右),在《九成宫醴泉铭》的不同拓本中,“巖”“書”“陽”三字的残缺状态有所不同,这恰恰类似于扩散模型(Diffusion Model)的前向扩散过程。
基于这个发现,笔者团队在顶会AAAI-24发表了一篇ACR(Ancient character restoration)的相关工作。该工作初步完成了ARMCD(Chinese Ancient Rubbing and Manuscript Character Dataset)数据集的构建,其中包含15,553个真实碑帖字样, 涵盖了自公元200年至1800年间超过200位书家的书写风格。提出了一种专业掩模合成方法来模拟真实的侵蚀效果,同时提出了一种基于扩散模型的自动修复方法Diff-ACR。

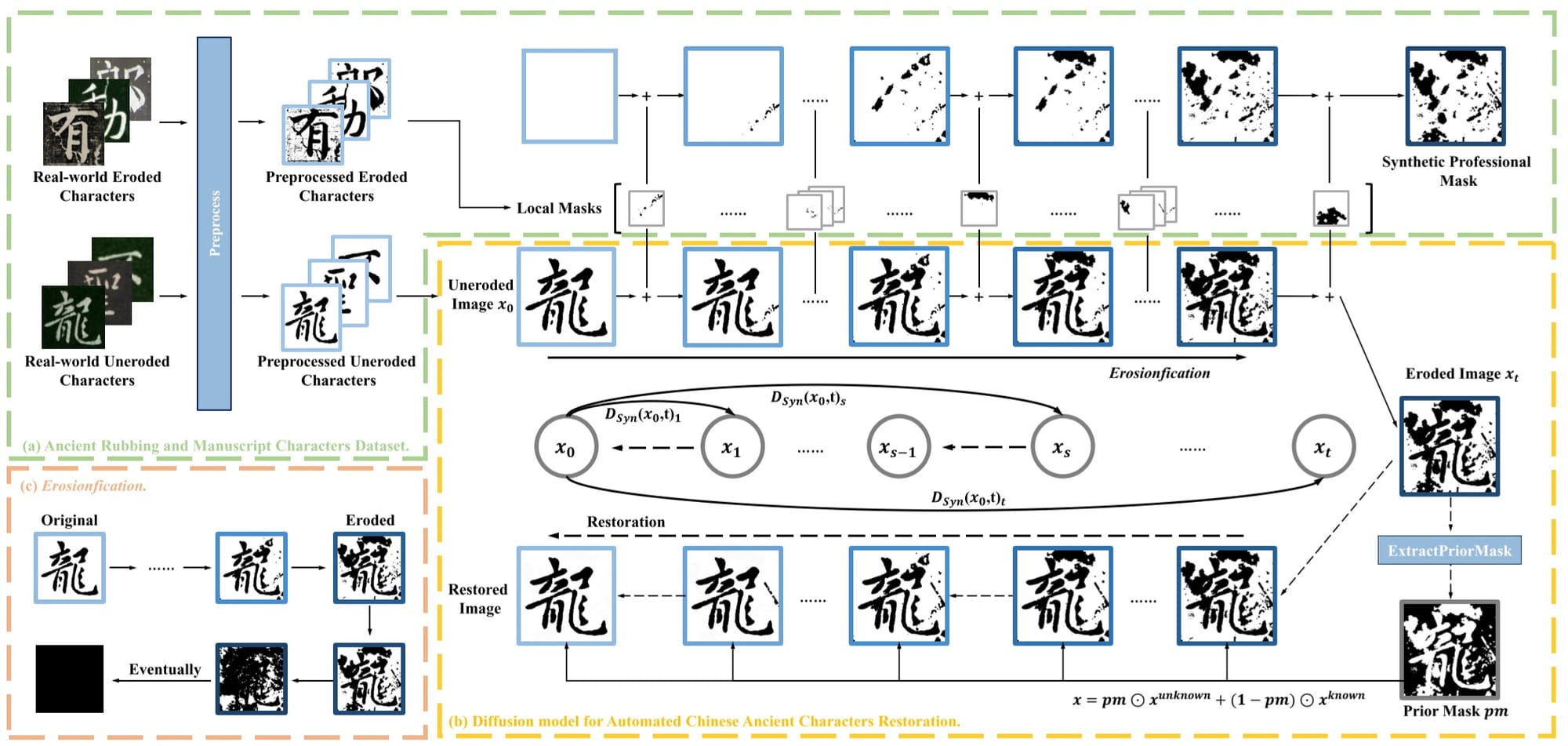

Code & Dataset: https://github.com/lhl322001/DiffACR
(2)古汉语语料库/知识库

不同于印欧语系自带分词,古汉语的特点是一字一词为主,多字词比如天下、诸侯、大夫、君子、社稷等需要做分词的标注。古籍数字化还需要完成基本的分词、断句、标点等工作。
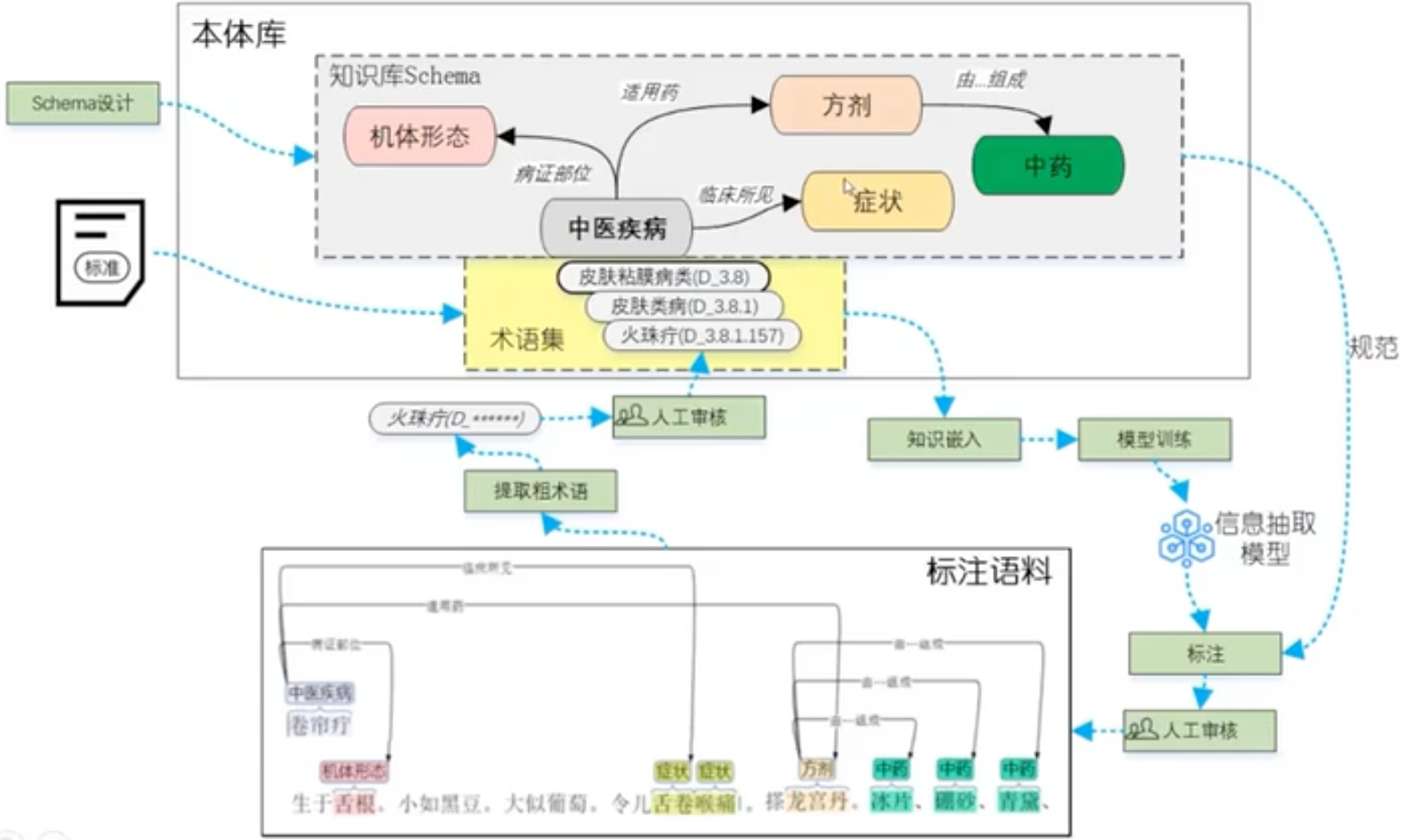
从语言学的角度,语料库包含词性标注和词义标注,方可支持词汇级的检索。进一步需要知识性的标注(知识库),特别是对于人物、地点、年代、组织、事件、概念和术语的标注,从而应用于文献学、历史学、文化传播和国学教育等领域。比如,对于秦始皇(始皇帝、始皇、秦王政、政、吕政、赵政、公子政)来说,这些词指代同一个人物概念,如果语料库仅仅支持字符串的检索是远远不够的。这就需要针对人名、地名、事件和年代做专名/命名实体(Named Entity)的标注。
举例:LDC语料库(Linguistic Data Consortium),收录语料库(corpora)900余个,涉及语言包括英语、汉语、阿拉伯语、波斯语、土耳其语、格鲁吉亚语、普什图语等。每年增加30-36个新资源。 LDC语言数据联盟是由大学、图书馆、公司和政府研究实验室组成的语言公开联盟,隶属于宾夕法尼亚大学文理学院(School of Arts and Sciences),成立于1992年,主要负责科研语言资源的收集、保存与管理分发。
举例:古汉语标记语料库(Academia Sinica Ancient Chinese Corpus) ,建構始於一九九0年,創始者為黃居仁(台湾語言所研究員)、譚樸森(英國倫敦大學亞非學院教授)、陳克健(台湾資訊所研究員)、魏培泉(台湾語言所研究員)等,最初的經費來源為蔣經國基金會及中央研究院歷史語言研究所,目標是蒐集上古漢語的素語料。素語料庫的構建自此未曾停歇,語料也由上古漢語擴充到中古漢語和近代漢語。
举例:BCC汉语语料库(北京语言大学),总字数约 95 亿字,包括:报刊(20 亿)、文学(30 亿)、综合(19 亿)、古汉语(20 亿)和对话(6 亿,来自微博和影视字幕)等多领域语料,是可以全面反映当今社会语言生活的大规模语料库。
语料库/知识库的文本标注成本巨大,需要运用自然语言理解领域的实体挖掘(命名实体识别NER,如SiKuBert+BiLSTM+CRF模型)、属性抽取、关系抽取等技术完成自动标注,再结合人工的校对。
举例:古汉语的自然语言理解(NLP)评测基准
https://github.com/CIRCSE/LT4HALA

基于文本标注,结合计算语言学和可视化技术,可以进一步挖掘人物社交关系(同一句中人物的同现网络)、人物旅行距离、人物地点的年代分布、地名时间热力图、人物时空地图、历史事件关系(如安史之乱背景相关的诗词)、意向情感关系(诗词中的名词性意象与表达的情感)等等。
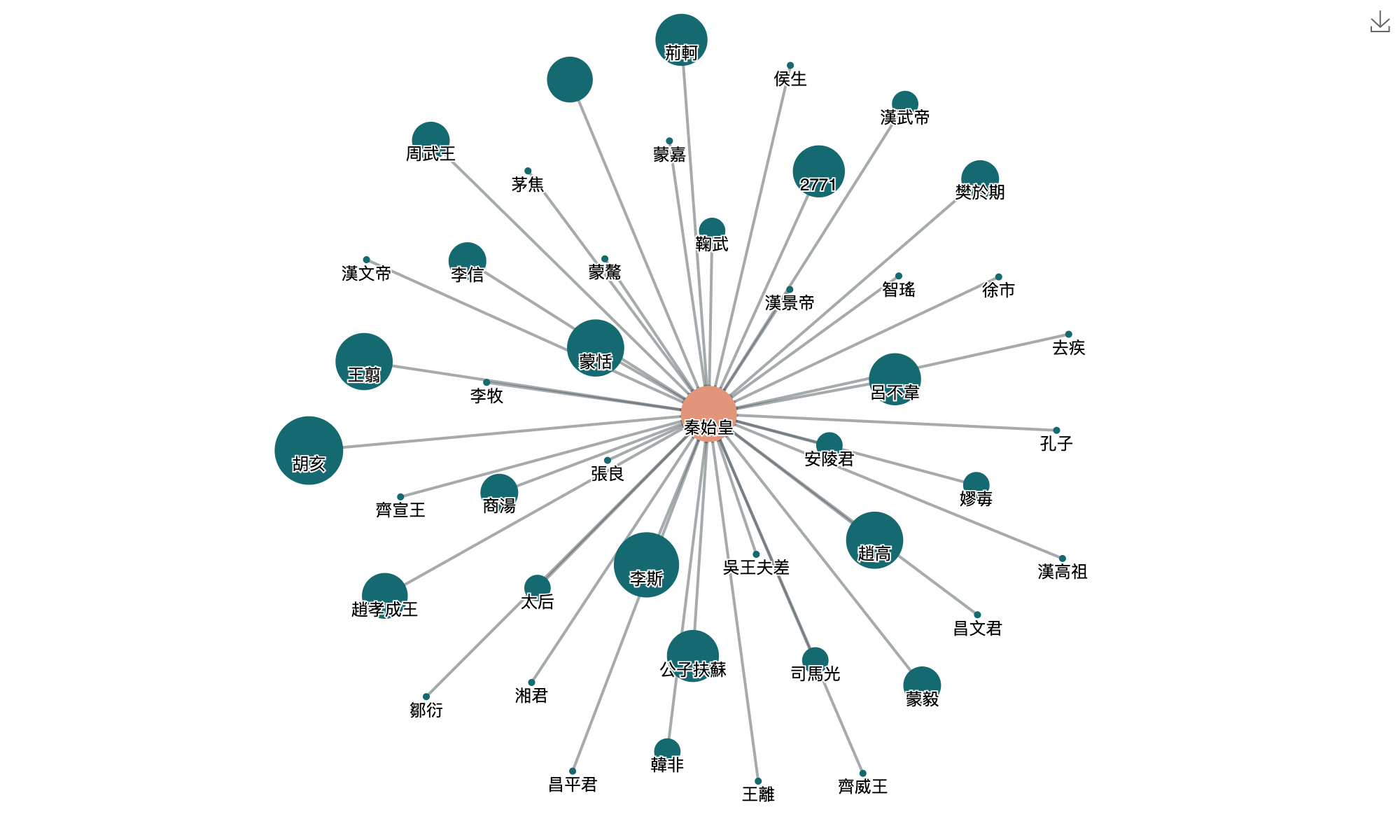
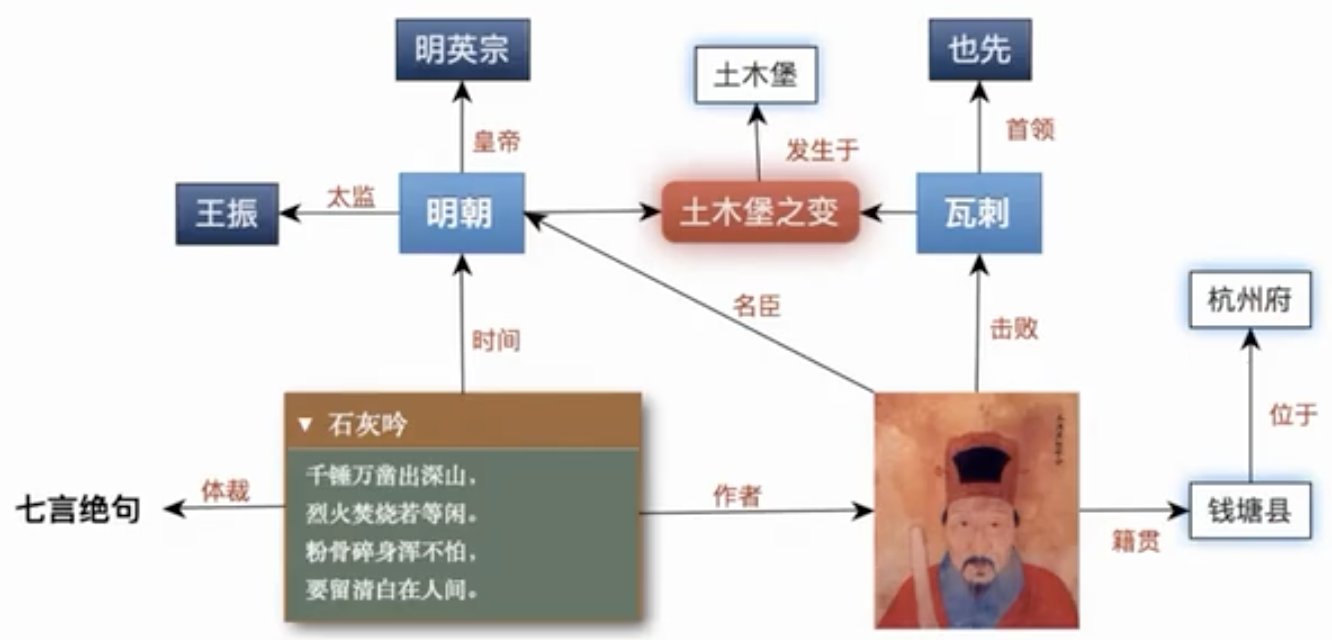
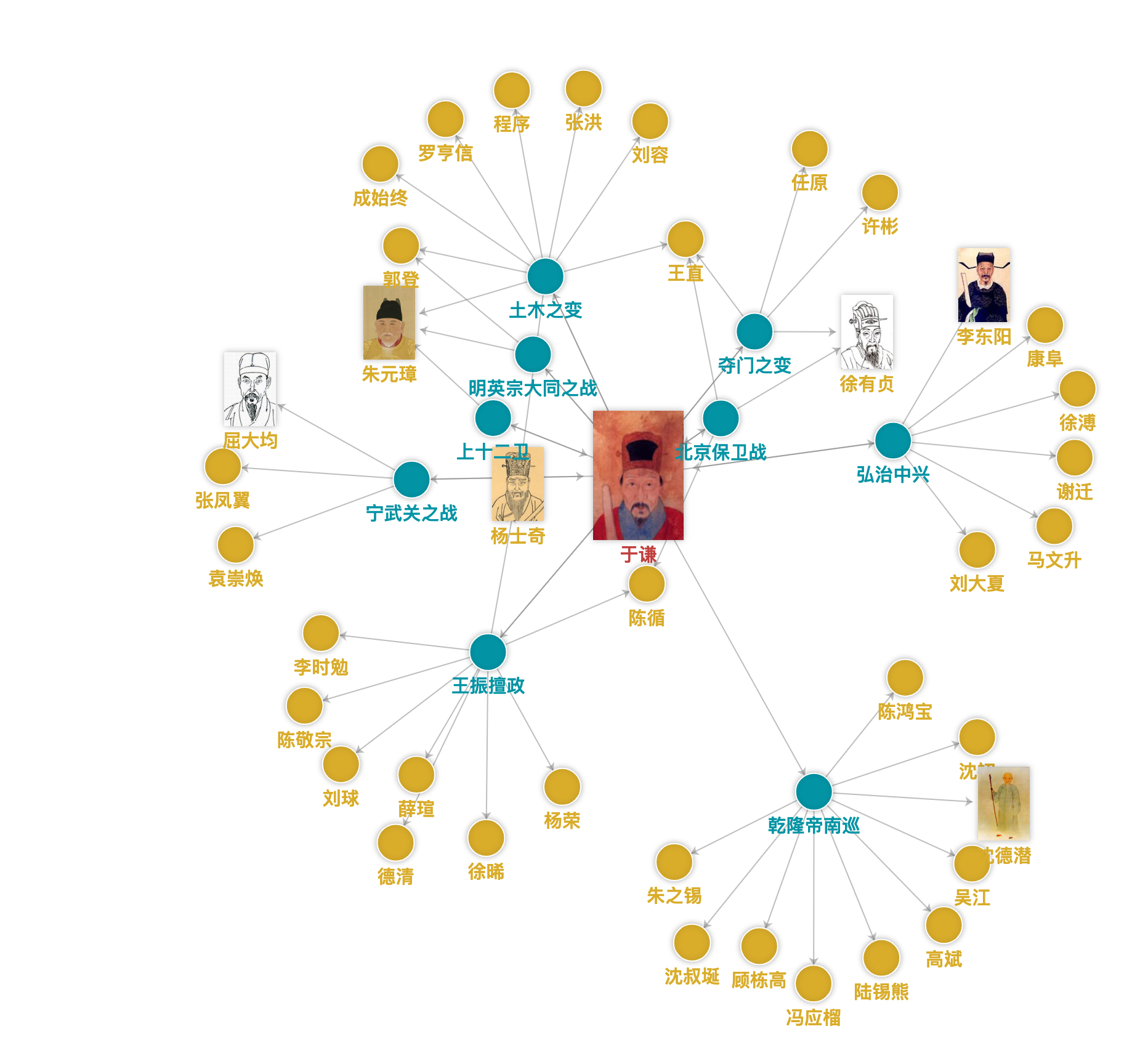
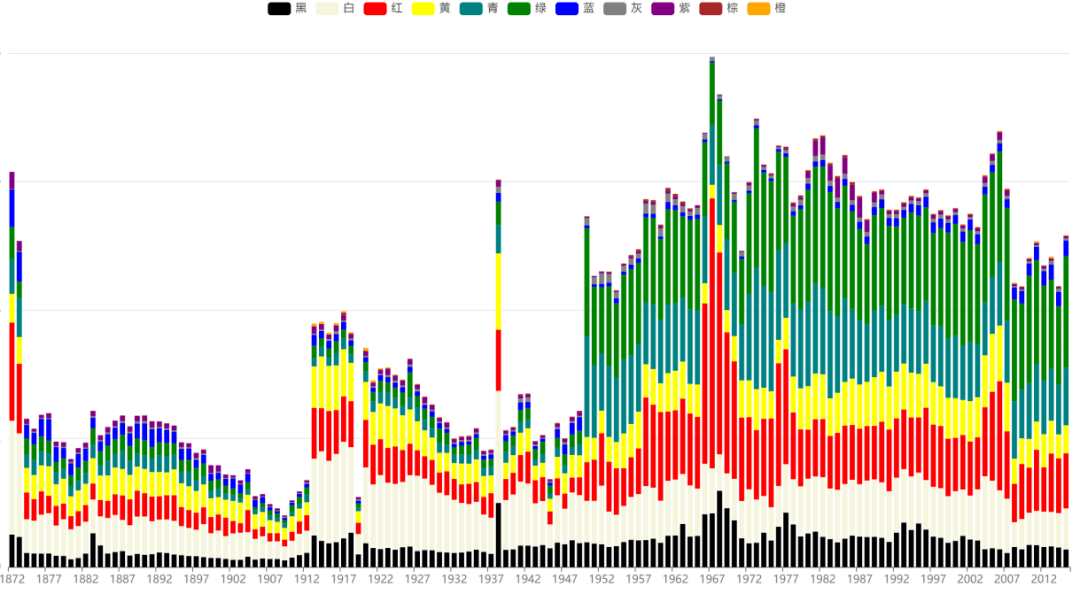
举例:中华诗词图谱(中科院软件所)诗词的立体化展示和理解
现存问题:
- 更精准、更全面的语料库构建, 文体演变所带来的分词问题仍旧是一个存在争议的难点;
- 多模态数据融合,包含文献文本、实物藏品、图像、语音等多模态数据,例如上述碑帖古籍的实物/实地图像、拓本图像和释文。
- 大规模的自动化分析与标准化评测;
- 更好的人机交互/跨平台的应用。
(3)数据与知识驱动的碑帖文本预测
碑刻(拓片)图像质量退化带来的残缺字识别难题,并不一定需要先完成字符修复,也可以基于残破构件,联合大语言模型的强大文本预测能力,直接进行文本预测。
未完待续。。。